VIP Innovations | A Tightly Coupled AI-ISP Vision Processor
原創 OpenASIC
各位朋友們,我們新開一個專欄,陸續介紹VIP實驗室在各大期刊會議上發表的論文和科研工作,還請大家多多關注!
本期介紹復旦大學VIP實驗室于2024年發表在IEEE TCSVT期刊的工作,這篇文章的題目為《A Tightly Coupled AI-ISP Vision Processor》。
全文速覽
為了實現高質量和高分辨率的圖像處理,本工作提出了一種新的視覺處理器,該處理器促進了深度學習增強型圖像處理流水線的發展。
• 在系統層面,通過確認分而治之的方法對于協調傳統圖像處理與圖像增強網絡至關重要,我們開發了一個緊密耦合的系統,并采用了strip-tile轉換數據流,以實現在ISP和深度學習加速器DLA之間進行細粒度低延遲的數據交互。
• 在架構層面,我們設計了21個高效的圖像處理模塊用于構建傳統的ISP流水線、基于tile-based strip layer fusion的DLA,以及一個可編程像素池PPP,支持ISP和DLA的數據訪問模式。
• 在軟硬件協同設計層面,我們提出了一套綜合的優化框架,旨在解決網絡實現的開銷問題,同時保持圖像質量。
• 最后,對AI-ISP視覺處理器的評估顯示,EMA訪問減少了53.95%,延遲降低了35.51%,且處理器內部SRAM開銷極小。高效處理超高清(UHD)分辨率的圖像,最高可達每秒168.5幀的吞吐。
Introduction
由于自動駕駛、AR/VR、生物醫學設備等領域的快速成長,對高質量圖像處理的需求顯著增加。ISP在這個演變過程中扮演著關鍵角色,然而隨著應用數量的增長以及光照條件的變化,參數擴展使得調校過程變得更加復雜。ISP通常由數十個模塊組成,每個模塊具有幾十到數千個可調參數,這使得實施一個統一的硬件設計以適應各種應用場景變得非常具有挑戰性。
近年來隨著深度學習的發展,圖像增強網絡取得了實質性進展,所提供的圖像質量超越了傳統圖像處理方法。此外,通過在定制的數據集上訓練這些網絡,可以在多種應用場景中進行優化和應用,而無需大量的手動干預。因此,通過結合傳統方法和深度學習方法的優勢,將網絡與ISP協同集成,為更高效和高質量的圖像處理流水線鋪平了道路。通用處理器的設計加速分類和檢測網絡已經得到了廣泛研究。
然而,由于圖像分辨率限制及其網絡結構,圖像增強網絡的硬件加速通常需要較大的片上內存占用,并涉及大量的外部存儲器訪問(EMA),這使得通用處理器難以在資源有限的情況下實現實時性能。
此外,先前的研究很少探討ISP與網絡處理器的硬件集成,通常將它們視為片上系統中的獨立模塊。如圖1所示,在ISP完成全幀圖像處理后,圖像才會被送入處理器進行后處理,這導致了端到端延遲較高。與片外存儲器的粗粒度數據交互進一步加劇了EMA問題。
因此,設計一個特定領域的深度學習加速器DLA和更細粒度的數據流對于更高效的圖像處理至關重要。
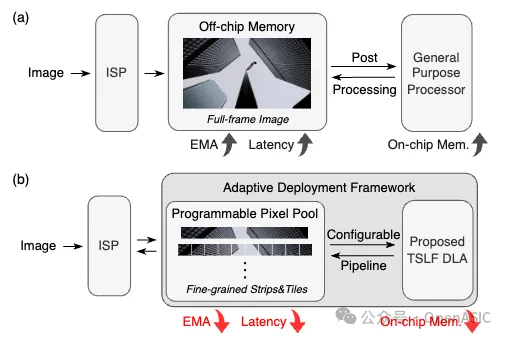
圖1
Dataflow And Architecture
本文所提出的AI-ISP視覺處理器的系統架構,旨在支持深度學習增強型圖像處理流水線,如圖2中展示。
在這個系統中,ISP的圖像處理模塊針對經典算法進行了定制化設計,并可以根據具體應用靈活地串聯形成子流水線。每個模塊主要由一個局部濾波器和line buffer組成。通過移位寄存器對存儲在line buffer中的多個圖像行執行滑動窗口操作,將數據發送到濾波器中,使用各種經典算法進行處理。
另一方面,開發了基于tile-based strip layer fusion的DLA,以加速多種集成的圖像增強網絡。另外,構建了一個可編程像素池(PPP),它包含strip buffer組,使得ISP與DLA之間能夠實現像素通信,從而達到緊密耦合的集成。為了促進細粒度的片上數據傳輸,設計了strip-tile轉換(STC)數據流。
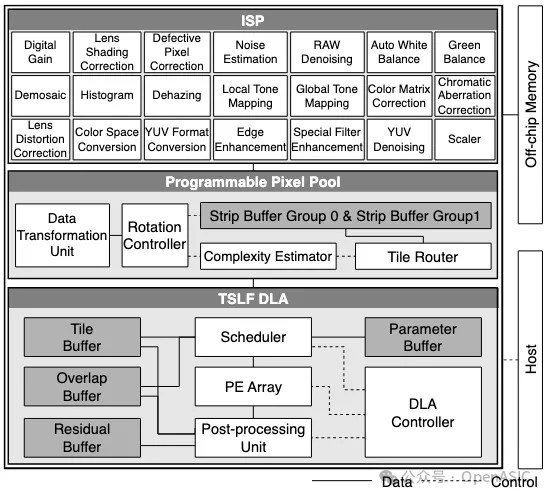
圖2
Overview of System Workflow
strip指的是圖像的一個片段,其寬度與整個圖像的寬度對齊,高度則由設計空間探索所決定。以一個strip為例,圖4展示了AI-ISP系統的工作流程。
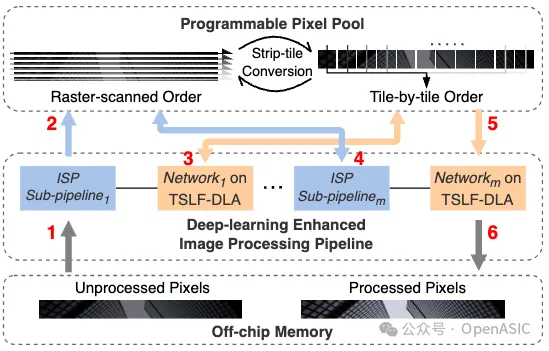
圖3
在系統操作之前,未處理的像素存儲在片外存儲器中。第一個ISP子流水線讀取每個strip的像素,進行處理,并將其寫入PPP。隨后,該strip會依次被送入后續的圖像增強網絡和ISP子流水線。
在PPP內,執行STC數據流,支持ISP和DLA的不同strip訪問模式。當DLA處理strip內的每個tile時,它遵循tile-based strip layer fusion。一旦流水線中的最后一個網絡完成其操作,處理后的像素就會被寫回到片外存儲器。
STC Dataflow and Hardware Mapping
來自ISP的像素流遵循光柵掃描順序,以行為最細粒度,而DLA則利用特征圖tile作為最細粒度來受益于數據局部性。通過利用這些不同的數據訪問模式,我們提出了STC數據流。
在部署深度學習增強型圖像處理流水線時,STC數據流首先將未處理的光柵掃描像素流組織成一個strip。然后,這個strip從左到右被轉換為tile,作為DLA的輸入。網絡推理完成后,輸出的tile被重新轉換回strip,并且圖像行隨后依次送入下游的ISP子流水線。
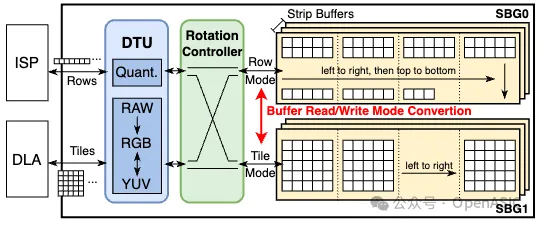
圖4
為了提供STC數據流的硬件支持,我們引入了PPP。如圖5所示,它由兩個strip buffer組(SBG)組成,每個組中的strip buffer數量由圖像增強網絡的最大輸入或輸出通道數決定。每個strip buffer存儲單通道的數據。
當PPP與ISP進行逐行數據處理交互時,像素流將在其中一個buffer組的多個strip buffer中存儲在相同的地址上。同時,DLA采用基于tile的數據處理方式使用另一個buffer組。通過將buffer劃分為多個bank并實施不同的地址管理邏輯,可以實現strip buffer的兩種數據訪問模式。旋轉控制器管理strip buffer的讀/寫模式和數據重用。當ISP和DLA分別完成其對應的SBG中的strip處理后,會發生模式轉換,即從ISP向DLA提供strip或相反。
此外,為了解決ISP和DLA之間的數據差異,我們在PPP內部設計了一個數據轉換單元(DTU)。該單元負責執行不同位寬的數據量化和反量化,以及促進不同圖像格式(如RAW、RGB和YUV)之間的像素級轉換。
Tile-based Strip Layer Fusion
先前關于層融合的研究可以分為兩種變體:基于line buffer的方法和基于金字塔的方法。如圖5(a)(b)所示,在計算輸出特征圖時,這兩種方法都需要存儲具有長重用距離的overlap。基于line buffer的方法優先考慮每個tile的向下處理,但這與ISP固有的strip處理優先相矛盾。而基于金字塔的方法則受到累積overlap和tile尺寸的影響,導致顯著的存儲或重新計算開銷。

圖5
為了解決這些挑戰,我們引入了tile-based strip layer fusion(TSLF),該方法涉及從一個strip中收集的tile,并按順序進行處理。這種方法與系統級STC數據流的處理順序一致,同時減少了具有長重用距離的overlap存儲負擔。
所提出的層融合方法包括兩個階段:strip內處理(intra-strip process)和strip間處理(inter-strip process)。
1. Intra-Strip Process.
在STC數據流中,DLA按照從左到右的順序處理strip內的每個tile。如圖(c)所示,strip內處理的主要目的是最小化tile之間overlap域造成的內存開銷。
這種類型的overlap一旦被存儲,就可以立即用于后續tile的處理,并且可以被視為具有短重用距離。考慮到基于金字塔的層融合,每一層的輸出特征圖既包括新生成的特征圖,也包括用于下一層計算的overlap部分。相比之下,TSLF僅專注于影響新生成部分的輸入特征圖。
當獲得一個新生成的輸出tile時,通過整合之前緩存的overlap列,可以在下一層立即進行輸出tile的計算。同時,為每個層存儲下一個tile的overlap列。我們使用一個overlap buffer來存儲相鄰tile之間的overlap。
為了最小化片上內存開銷,overlap列的寬度Wcol必須盡可能小。在TSLF中,Wcol值被設置為K−1,這意味著緩存的overlap列寬度僅由當前層的卷積核大小決定。這種方法確保了除最左邊和最右邊的tile外,每層的輸出tile寬度與輸入tile相匹配。
盡管包含填充會導致最外層tile的寬度在各層間有所變化,但它們在DLA上的處理流程與常規tile相同,對計算單元的利用率影響微乎其微。
2. Inter-Strip Process.
strip間處理的主要思想是消除相鄰strip之間的overlap。如圖6(a)所示,對于兩個連續的strip,strip(i+1)的計算依賴于在strip(i)推理過程中緩存的所有中間特征圖的最后Ky−1行。這種類型的overlap具有長重用距離,可能導致顯著的內存開銷。為了解決這個問題,TSLF對各個strip執行卷積操作,并在每一層的輸入strip的頂部和底部應用填充以避免依賴于overlap。將填充大小P設置為(Ky−1)/2,使得每一層可以直接進行推理,且strip的高度在整個過程中保持一致。
然而,直接處理每個獨立的strip然后將它們連接起來會導致邊界效應。為了減輕strip連接對圖像質量的影響,如圖6(b)所示,我們選擇引入初始輸入strip和網絡最終輸出strip的共享邊界區域和基底區域。需要注意的是,這里的共享邊界與層融合中的長重用距離overlap不同。這種邊界區域僅出現在網絡的輸入和輸出strip上,對于一個圖像增強網絡來說,通常包含1個或3個通道。因此,相比中間特征圖,網絡的存儲需求大大減少。
我們采用一種拼接策略來恢復輸出特征圖。如圖6(c)所示,每個strip保留其邊界的半部分,然后將這些邊界連接在一起。通過這種方法,可以在最小化內存開銷的同時,確保strip間的平滑過渡,從而保證圖像質量不受影響。
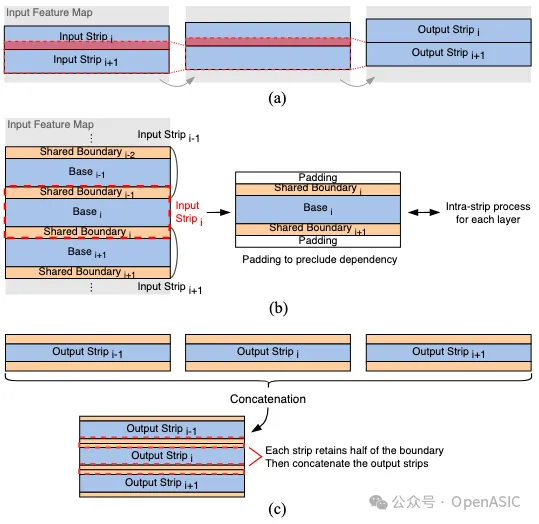
圖6
TSLF DLA Architecture

圖7
如圖7所示,為了支持TSLF,我們設計了一種專用的DLA架構。主機離線編譯網絡為指令,這些指令包含了層數、操作類型以及每層的維度信息。
控制器從主機接收這些指令,對其進行解碼,并向其他模塊分發控制信號。通過系統AXI總線實現與主機和片外存儲器的數據交互。在預加載指令和網絡參數完成后,DLA會在PPP內完成初始STC后啟動基于tile的計算。主要計算單元是PE陣列,包含2,048個乘累加器。
根據每個調度,PE陣列對一個輸出特征子tile進行并行處理,該子tile寬度為32,高度為4,涉及4個輸入通道和4個輸出通道。每個PE包含一個乘累加(MAC)單元和寄存器,采用輸出靜止數據流以減輕圖像增強網絡推理過程中對特征數據移動的需求。對于輸入值為零的計算進行旁路以減少功耗。為了確保高利用率,在每個PE中卷積核的寬高計算在時間維度被展開。
調度器和后處理單元(PPU)提供了對TSLF strip內處理和strip間處理的支持。調度器通過直接內存訪問(DMA)從buffer獲取特征和權重數據。一個由多路復用器和移位寄存器實現的二維數據移位器將填充和strip內overlap與輸入特征tile拼接起來,使得PE陣列可以在迭代中重用數據。完成所有輸入通道的迭代后,子tile被發送到PPU。
PPU由多個單元組成,旨在加速網絡推理過程中的非卷積操作,包括部分和累積、激活函數、殘差累積、量化、上采樣和strip間邊界處理。采用了融合操作流水線以減少中間數據的存儲器訪問。當網絡中不存在相應的操作時,相關單元可以被旁路。寫回邏輯裁剪輸出strip的一半共享邊界區域,并將結果寫回到tile buffer中對應的地址。
Systematic Optimizations
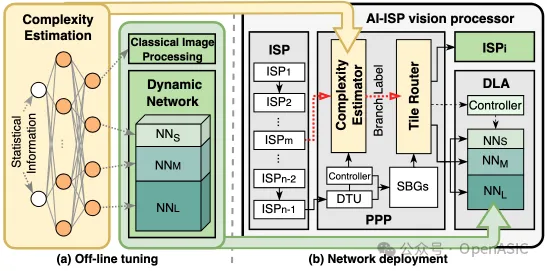
圖8
我們開發了一個新穎的圖像增強網絡部署框架,如圖8所示。該框架提供了以下優勢:
• (1)遵循STC數據流的固有處理順序:基于tile的自適應圖像增強充分利用了DLA和ISP。通過將部分tile路由到ISP或容量較小的網絡中進行處理,此方法顯著減少了計算負擔,同時保持了整體圖像質量。
• (2)與先前工作不同:我們的方法利用來自ISP子流水線的統計信息作為先驗知識來估計每個輸入tile的復雜度,而不是使用多個卷積層來估計復雜度,從而減少了復雜度評估的開銷。
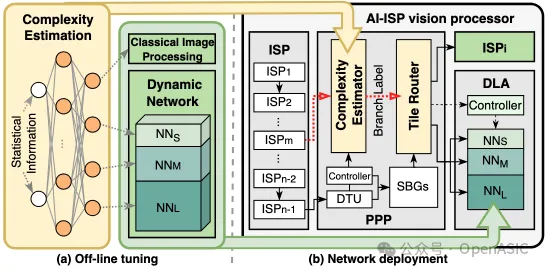
1. 離線調優
基于tile的自適應圖像處理包含四個不同的分支:ISP及其對應的三分支動態網絡。動態網絡由NNS、NNM、NNL組成。這三個網絡結構相同,但每層的通道數不同,其中NNL與原始網絡相同。這些網絡分別使用根據其增強難度級別標注的tile數據集進行了獨立訓練。為了引導圖像tile進入適當的分支,我們設計了一個輕量級的復雜度估算網絡。該網絡采用簡單的全連接層構建,每一層后跟隨ReLU激活函數以幫助排序tile復雜度。在系統運行期間,復雜度估算器收集每個圖像tile的均值和方差作為網絡的輸入統計信息。經過計算后生成一個概率向量。
2. 硬件修改與部署
PPP集成了一個復雜度估計模塊,用于預測每個tile的分支標簽。該模塊專門為全連接網絡構建,并在運行時加載預訓練的權重。由于復雜度估算網絡的輕量化特性,該模塊能夠以最小的硬件開銷實現實時分支預測。此外,還設計了router模塊,根據tile標簽將其導向ISP或DLA進行自適應圖像處理。得益于STC數據流,這種基于tile的ISP strip內像素計算不會產生任何額外的存儲器訪問開銷。
Evaluation
TSLF DLA Evaluation
下圖9提供了我們提出的TSLF DLA在特征圖的EMA和片上內存占用方面的比較分析。
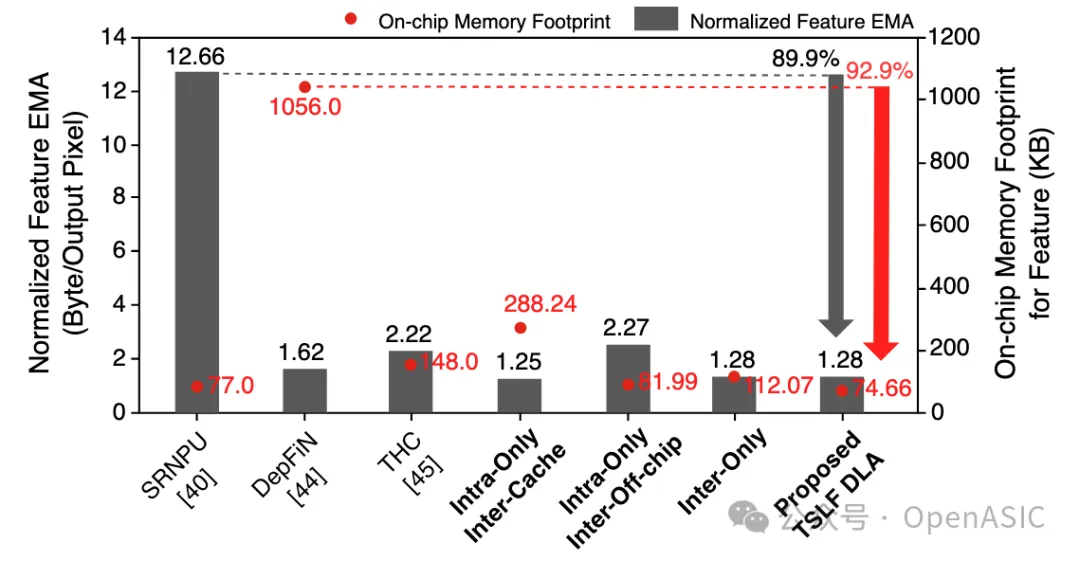
圖9
在TSLF DLA中,歸一化的EMA為每輸出像素1.28字節,相比SRNPU減少了89.9%。片上內存用于存儲條帶內處理所需的特征圖tile和overlap。總容量為74.66 KB的情況下,我們的方法相對于DepFiN減少了92.9%的片上內存占用。
此外,從圖9中最后四列可以看出,當僅使用條帶內處理時,條帶間overlap要么需要更多的片上內存,要么需要存儲在片外,導致EMA增加。由于條帶間overlap的長重用距離,這種開銷隨著網絡通道數或特征圖分辨率的增加變得更加顯著。當僅使用條帶間處理時,每一層的條帶內overlap寬度累積,導致片上內存占用增加。相比之下,同時使用條帶間處理和條帶內處理的TSLF表現出最少的片上內存占用和EMA。
如表1所示,TSLF DLA在應用、片上內存大小和系統耦合方面優于最先進的圖像增強專用加速器。
具體來說,TSLF DLA支持廣泛的圖像增強網絡,并可以無縫集成到各種圖像處理場景中。
FPGA和ASIC實現的評估報告分別達到0.74 TOPS和3.28 TOPS的峰值性能。它在800 MHz、0.72V下消耗307 mW功率,峰值能效為10.69 TOPS/W。歸一化的邏輯面積效率計算為1.92 TOPS/mm²。
我們的設計在ASIC上以117.3 fps生成UHD分辨率輸出,在FPGA上達到26.4 fps。總共分配了119 KB的片上內存來存儲特征圖tile、overlap、殘差和網絡參數。
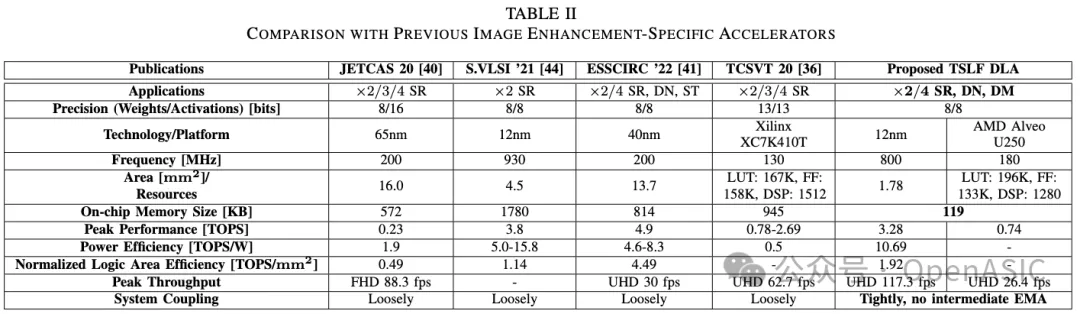
表2
System Level Analysis
為了評估緊耦合AI-ISP的優勢,我們在生成單個UHD圖像時比較了以下系統配置:
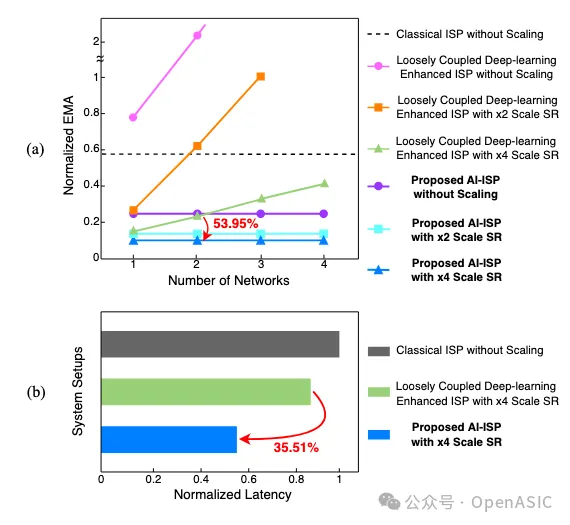
• (1)ISP:直接在原始分辨率圖像上進行處理。
• (2)松耦合的深度學習增強型ISP:ISP以全幀粒度與DLA交互,并使用片外存儲器進行數據交換。
• (3)我們提出的緊密耦合AI-ISP視覺處理器:利用PPP在ISP和DLA之間執行細粒度的STC數據流。
在我們的分析中,為了符合實際使用場景,SR的輸入和輸出通道數設置為1,而對于其他圖像增強網絡,則設置為3。

表2
圖3(a)展示了上述系統在集成不同數量網絡時所需的EMA對比。盡管SR的應用減少了EMA,但在圖像處理流水線中添加更多網絡時,松耦合的深度學習增強型ISP表現出顯著增加的EMA。相比之下,由于STC數據流和PPP的數據重用,我們的AI-ISP的EMA保持恒定,僅依賴于輸入和輸出圖像的大小,顯示出可擴展性。具體來說,通過結合DN-DM網絡和×4 SR,AI-ISP相比松耦合版本實現了53.95%的EMA減少。
此外,我們在FPGA實現的不同系統配置下對這些兩個網絡進行了延遲比較。直接處理UHD輸入圖像的ISP產生了最長的延遲。通過細粒度的數據交互和分支,AI-ISP比松耦合的深度學習增強型ISP延遲降低了35.51%。
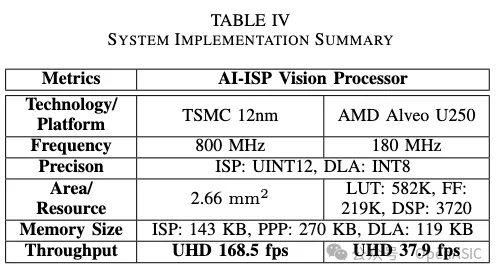
表3
在整合ISP、PPP和TSLF DLA后,使用TSMC 12nm工藝庫實現的AI-ISP總面積為2.66 mm²。AI-ISP的吞吐量由具有較高計算復雜度的DLA決定。通過提出的自適應部署框架,進一步減少了DLA上的網絡工作負載。基于代表大多數現實場景的DIV2K數據集測試結果,該系統的吞吐量在UHD分辨率下最高可以達到168.5 fps。
關注我們
實驗室網站 http://viplab.fudan.edu.cn
微信公眾號 OpenASIC
官方網站 www.openasic.org
知乎專欄 http://zhuanlan.zhihu.com/viplab